2.1 General HPC Cluster Policies
2.1.1 Cluster General Login or Interactive Node Policy
- The interactive or login nodes are the front end interface nodes for access to the HPC clusters. Each cluster has a set of two general login nodes associated with them. For example if you ssh into "kingspeak.chpc.utah.edu," you will actually be connected to one of the two general kingspeak nodes, either kingspeak1 or kingspeak2. In the protected environment, there are redwood1 and redwood2. In addition to the cluster front end nodes, CHPC provides a set of additional login nodes, the frisco nodes in the general environment and the bristlecone nodes in the protected environment, for limited interactive work. For intensive interactive work you must use the batch system.
- The login nodes are your interface with the computational nodes and are where you interact with the batch system. Please see our User Guides for details. Processes run directly on these nodes should be limited to tasks such as editing, data staging and management, lightweight data analysis, compiling codes and debugging, as long as it is not resource intensive (memory, cpu, network and/or i/o). In terms of i/o, if you are doing large transfers of data please make use of the Data Transfer nodes instead if the login nodes. The policies for acceptable usage of the frisco/bristlecone nodes is more relaxed than the cluster interactive nodes, but is still limited. Our goal is to limit cpu usage to the equivalent of 15 core minutes at or under 4 GB memory usage on the cluster interactive nodes or 120 core minutes at or under 12 GB memory usage on the frisco/bristlecone nodes.
- We have a service named Arbiter, which leverages linux's cgroups (control groups)
running on these resources in order to monitor cpu and memory usage and enforce the
policy. Arbiter works with a set of maximum usage limits and threshold levels. When
a user is at or above the threshold levels, they start to accrue a "badness score".
If a user remains at or above these threshold limits, the badness score increases,
until the user reaches a badness score that results in a "penalty" condition, which
further limits the cpu and memory usage accessible to the user, with the goal of sufficiently
throttling usage in order to not violate the established usage policy and so that
others are not impacted by the excessive use of a shared resource. Arbiter maintains
a history of penalty status, resulting in a time period before previous behavior
is not a factor on the penalties imposed. Users will receive an email message from
the Arbiter script when they enter and exit penalty status; the email will include
a listing of their high impact processes, and a graph that shows their cpu and memory
usage over a period of time. Here is an example message:
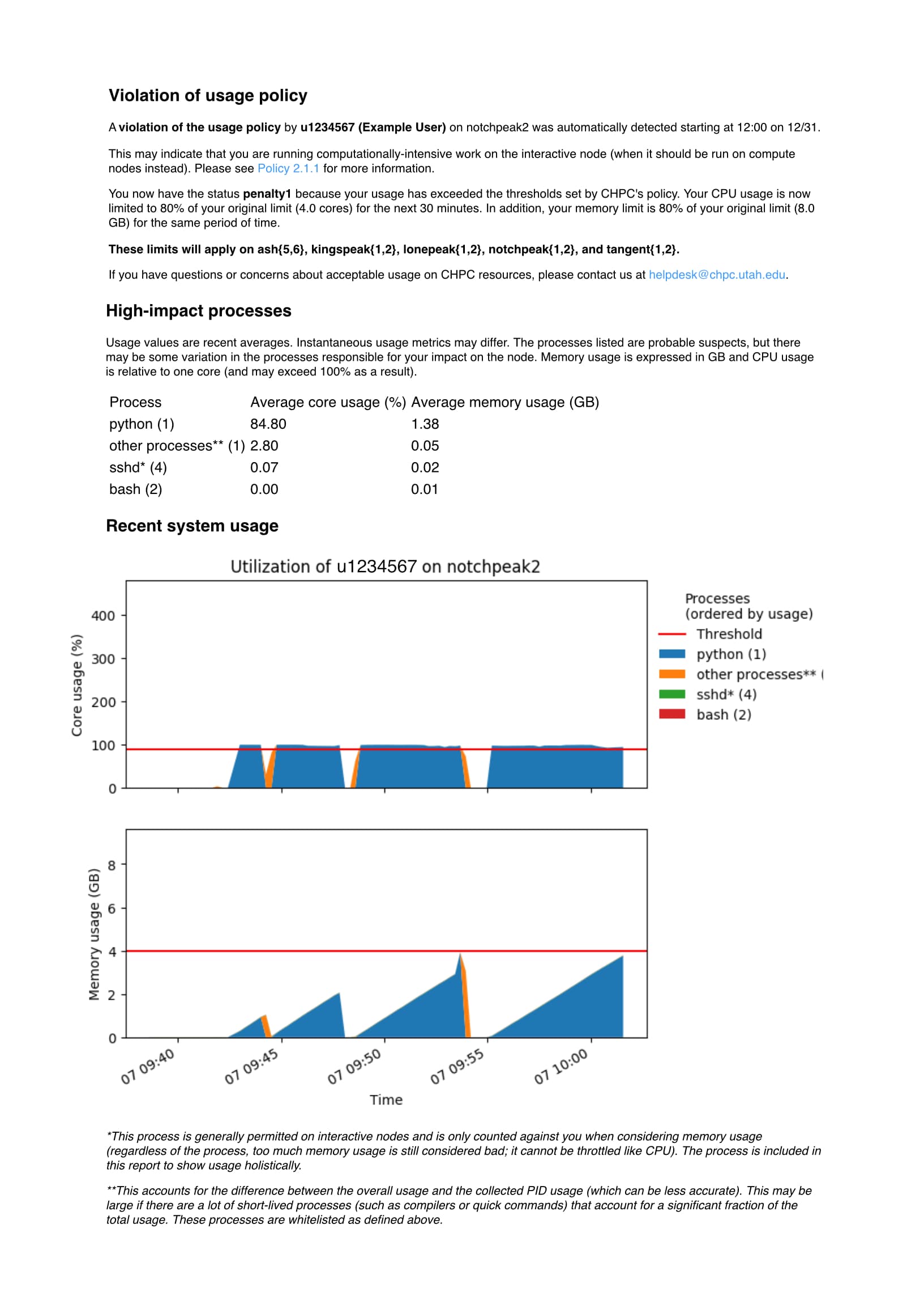
- Nodes are grouped, and when you are put into penalty on one node of the group, you are in penalty on all of the nodes in that group. The two node groupings in the general environment are (1) the frisco nodes (currently frisco1 through frisco8) and (2) the cluster interactive nodes (currently granite{1,2}, notchpeak{1,2}, kingspeak{1,2}, and lonepeak{1,2}). In the protected environment there are the (1) bristlecone nodes (currently bristlecone1 and bristlecone2) and (2) the cluster interactive nodes of redwood{1,2}
- Below is a description of the current implementation and settings being used:
- Linux's cgroups (control groups) set a maximum limit on the resources a user can access on the interactive resources. Currently the cgroup limits are 4 cores and 8GB memory on the cluster interactive nodes and 12 cores and 24GB of memory on the frisco/bristlecone nodes. This is a limit for all processes that a user has on a given node. These limits are referred to as the "normal" status and set the maximum usage which a user cannot exceed. While the aggregate cpu usage can never exceed the cgroup core limit, when the aggregate total memory usage reaches this cgroup memory limit the out of memory (OOM) killer will start to kill processes to reduce the memory usage.
- The Arbiter script also sets the threshold or trigger levels. On the interactive nodes this level is set at about 1 core and 4 GB memory; on the frisco/bristlecone nodes it is set to about 4 cores and 16 GB memory.
- At a badness score reached after the equivalent of running for about 15 minutes at a load of about 1 core and/or using 4 GB of memory on the interactive node, a user is put into penalty 1; on frisco/bristlecone, the badness accrual is set such that the penalty 1 is reached in about 60 minutes when running at a load of 4 cores and/or using 16 GB of memory. Note that running at a higher load will decrease the time it takes to reach the badness score which invokes the penalty status proportionally, e.g., on an interactive node, a user running at a load of about 2 cores will reach the badness score to be put into penalty in about 7.5 minutes.
- Penalty 1 status limits the user to 80% of the original limits of both cores and memory for 30 minutes before returning the user back to normal status, with a badness score of 0.
- If the user does not address the conditions that put them into penalty status, their badness score will once again climb, leading to a penalty 2 status. Penalty 2 status limits the user to 50% of the original limits of both cores and memory for 60 minutes before returning the user back to normal status.
- If the user does not address the conditions that put them into penalty status, their badness score will again increase, leading to a penalty 3 status. Penalty 3 status limits the user to 30% of the original limits of both cores and memory for 120 minutes before returning the user back to normal status.
- If the user does not address the conditions that put them into penalty status, their badness score will again increase, leading to a return to penalty 3 status.
- Arbiter maintains a history, such that once a user returns to normal status and is no longer exceeding the thresholds, the last penalty status is decreased by 1 level each 3 hours. Therefore, a user who reached penalty 1 will take 3 hours, one who reached penalty 2 will take 6 hours stepping down to level 1 in 3 hours, etc, before their previous penalty status does not impact the penalties imposed by current usage.
2.1.2 Batch Policies (all clusters)
General Queuing Polices
- Users who have exhausted their allocation will not have their jobs dispatched unless there are available free cycles on the system. Preemption rules are determined on each cluster - see the cluster's scheduling polices (links below).
- There is a maximum number of nodes allowed per job set at approximately 1/2 of the general nodes on each cluster.
- Special access is given to a long qos to exceed the MAX walltime limit on a case-by-case basis. Please send any request for access to this qos to helpdesk@chpc.utah.edu with an explanation (job cannot be run under regular limits with checkpointing/restarts/more nodes). There is a limit of two nodes running with this qos at any given time.
- Exceptions, again on a case-by-case basis, can also be made to the maximum number of nodes allowed per job. Please contact chpc via helpdesk@chpc.utah.edu with an explanation of your need for an exception.
- Each of the computational clusters has its own set of scheduling policies pertaining to job limits, access and priorities. Please see the appropriate policy for the details of any particular cluster.
Reservations
Users may request to reserve nodes for special circumstances. The request must come from the PI/Faculty advisor of the user's research group and the group's allocation must be sufficient to cover the duration of the reservation. A reservation may be shared by multiple users. The maximum number of nodes allowed for a reservation is half the number of general nodes for the cluster the user is asking for. The maximum duration for reservations is two weeks. The PI/Faculty advisor should send a request to helpdesk@chpc.utah.edu with the following information:
- Which cluster
- Number of Nodes/Cores
- Starting date and time (please ask ahead by at least the MAX walltime for that cluster)
- Duration
- User or Users on the reservation
- Any special requirements (longer MAX walltime for example)
Owner-Guest
Owner-guest access is enabled on owner nodes on granite, notchpeak, kingspeak, and lonepeak. Jobs run in this manner are preemptable. To do so, you will need to specify a special account. Jobs using these preemption accounts will not count against your group's allocation. Jobs run in this manner should not use /scratch/local as this scratch space will not be cleaned when job is preempted nor is it accessible by the user running the guest job to retrieve any needed files.
To specify the owner-guest, use the partition cluster-guest (using the appropriate cluster name) and the account owner-guest; on ash the account for guest jobs is smithp-guest. Your job will be preempted if a job comes in from a user from the group of the owner whose node(s) your job received.
You can also target a specific owner group by using the PI name in your resource specification by using the slurm constraint definition. You can also target a specific core count by using constraint with the core count (specified as c#) or memory amount by using the slurm batch directive to specify memory. The use of these are described on the Slurm documentation page.
2.1.3 Kingspeak Job Scheduling Policy
Job Control
Jobs will be controlled through the batch system using SLURM.
- Node sharing. Node sharing is enabled by default as of January 2026.
- Allocations.This cluster is completely unallocated. All jobs on the general resources will run without allocation and without preemption. Allocations on owner nodes will be at the direction of node owners.
- Best effort to allocate nodes of same CPU speed
- Max time limit for jobs is 72 hours (on general nodes)
- Max nodes per job on the general nodes is set to approximately 1/2 of the total number of general nodes.
- Scheduling is set based on a current highest priority set for every job. We do have backfill enabled.
- Fairshare boost in priority at user level. Minimal boost to help users who haven't been running recently. Our Fairshare window is two weeks.
- Small relative to time small short jobs are given a boost for length of time in the queue as it relates to the wall time they have requested.
- Reward for parallelism. Set at the global level.
- Partitions
Partition Name Access Accounts Node/core count Memory Features Node specification kingspeak
all <pi> 32/512
12/240
4/8044 nodes with 64GB
4 nodes with 384GB
chpc, core count, memory kp[001-032,110-111,158-167,196-199] kingspeak-gpu by request kingspeak-gpu See gpu page for details kp[297-300] kingspeak-guest
all owner-guest sum of owners see owner nodes <owner>, core count, memory kp[033-099,101-108,112-157,229-237,246-296,301-344,346-358,363-364,368-387] <owner>-kp
restricted <owner>-kp use sinfo to see details use sinfo to see details <owner>, core count, memory kp[033-099,101-108,112-157,229-237,246-296,301-344,346-358,363-364,368-387] <owner>-gpu-kp restricted <owner>-gpu-kp See gpu page for details kp[359-362] kingspeak-gpu-guest by request kingspeak-gpu-guest See gpu page for details
kp[359-362]
- Partitions
- Job priorities
The majority of a job's priority is based on a quality of service definition or QOS. The following QOS's are defined:
QOS Priority Preempts Preempt Mode Flags GrpNodes MaxWall kingspeak 100000 kingspeak-freecycle cancel 48 3-00:00:00 (3 days) kingspeak-freecycle 10000 cancel NoReserve 48 3-00:00:00 kingspeak-guest 10000 cancel NoReserve all owner nodes 3-00:00:00 kingspeak-long 100000 kingspeak-freecycle cancel 48 14-00:00:00 (14 days) <owner>-kp 100000 kingspeak-guest cancel varies all owner nodes;
use sinfo command to
see per owner
set by owner
default is 14-00:00:00
- Interactive nodes. For general use there are two interactive nodes, kingspeak1.chpc.utah.edu and kingspeak2.chpc.utah.edu. Access either via kingspeak.chpc.utah.edu. There are also owner interactive nodes that are restricted to the owner group.
2.1.4 Lonepeak Job Scheduling Policy
Job Control
- Jobs will be controlled through the batch system using Slurm.
- Node sharing. Node sharing is enabled by defualt as of January 2026.
- Allocations. This cluster is completely unallocated. All jobs on the general resources will run without allocation and without preemption. Allocations on owner nodes will be at the direction of node owners.
- Max time limit for jobs will is 72 hours.
- Max nodes per job on the general nodes is set to approximately 1/2 of the total number of general nodes.
- Fairshare will be turned on.
- Scheduling is set based on the current highest priority set for every job.
- Reservations are allowed for users who show a need for the large memory available on these nodes. Reservations will be for a maximum window of two weeks and a maximum of 50% of the general nodes on the cluster will be allowed to be reserved at any given time. Reservations will be made on a first come first serve basis. Up to 96 hours may be needed for the reservation to start.
- Partitions
Partition Name Access Accounts Node/core count Memory Features Node specification lonepeak
all <pi> 191/2292
8/96
4/128
8/160
191 with 96GB
8 with 48 GB
4 with 1 TB
8 with 256GB
chpc, core count, memory lp[001-016,017-112,133-202,204-232] lonepeak-guest
all all sum of owners see owner nodes Varies <owner>-lp
restricted <owner>-lp, owner-guest 20/400
1/16
20 with 64 GB
1 with 128GB
<owner>, lp[113-132,233]
-
QOS Settings:
The majority of a job's priority will be set based on a quality of service definition or QOS.
QOS Priority Preempts Preempt Mode Flags GrpNodes MaxWall lonepeak 100000 cancel 99 3-00:00:00 (3 days) lonepeak-guest 10000 cancel NoReserve 20 3-00:00:00 lonepeak-long 100000 cancel 14-00:00:00 (14 days) <owner>-lp 100000 lonepeak-guest cancel varies 20
set by owner
default is 14-00:00:00
-
Interactive nodes. For general use there are two interactive nodes, lonepeak1.chpc.utah.edu and lonepeak2.chpc.utah.edu. Access either via lonepeak.chpc.utah.edu. There are also owner interactive nodes that are restricted to the owner group.
2.1.5 Notchpeak Job Scheduling Policy
Job Control
Jobs will be controlled through the batch system using SLURM.
- Node sharing. Node sharing is enabled by default as of January 2026.
- Allocations. Allocation on general nodes will be handled through the regular CHPC allocation committee. Allocations on owner nodes will be at the direction of node owners.
- Best effort to allocate nodes of same CPU speed
- Max time limit for jobs is 72 hours (on general nodes).
- Max nodes per job on the general nodes is set to approximately 1/2 of the total number of general nodes.
- Scheduling is set based on a current highest priority set for every job. We do have backfill enabled.
- Fairshare boost in priority at user level. Minimal boost to help users who haven't been running recently. Our Fairshare window is two weeks.
- Small relative to time small short jobs are given a boost for length of time in the queue as it relates to the wall time they have requested.
- Reward for parallelism. Set at the global level.
- Partitions
Partition Name Access Accounts Node/core count Memory Features Node specification notchpeak
all <pi> 65/3212 varies
chpcl amd or skl or csl; core count, memory varies notch[005-008,035-045,096-097,106-107,153-155,172-203] notchpeak-gpu by request notchpeak-gpu See gpu page and sinfo for details notchpeak-freecycle all all 65/3212 varies chpcl amd or skl or csl; core count, memory varies notch[005-008,035-045,096-097,106-107,153-155,172-203] notchpeak-guest
all owner-guest sum of owners see owner nodes Varies use sinfo to see details <owner>-np
restricted <owner>-np, owner-guest use sinfo to see details use sinfo to see details <owner>, core count use sinfo to see details notchpeak-gpu-guest
by request notchpeak-gpu-guest See gpu page and sinfo for details
- Partitions
- Job priorities
The majority of a job's priority is based on a quality of service definition or QOS. The following QOS's are defined:
QOS Priority Preempts Preempt Mode Flags GrpNodes MaxWall notchpeak 100000 notchpeak-freecycle cancel 65 3-00:00:00 (3 days) notchpeak-freecycle 10000 cancel NoReserve 65 3-00:00:00 notchpeak-guest 10000 cancel NoReserve all owner 3-00:00:00 notchpeak-long 100000 notchpeak-freecycle cancel 65 14-00:00:00 (14 days) <owner>-np 100000 notchpeak-guest cancel varies use sinfo to
see details
set by owner
default is 14-00:00:00
- Interactive nodes. For general use there are two interactive nodes, notchpeak1.chpc.utah.edu and notchpeak2.chpc.utah.edu. Access either via notchpeak.chpc.utah.edu. There are also owner interactive nodes that are restricted to the owner group.